
We’re very excited today to launch Papers API — a single endpoint to query 3M+ Research Papers. Paper’s API is what ScholarXIV is built on top of and is what’s utilized behind the scenes.
The Problem
For a long time, ScholarXIV utilized arXiv’s public API to access e-print content and metadata. As grateful as we are to arXiv for maintaining an open and interoperable ecosystem and providing their API, it wasn’t enough for the age of AI.
arXiv’s API limits are pretty low, and understandably so. The limits force you to make no more than one request every three seconds per user or organization, and you must make these requests from a single connection at a time (you can’t parallelize or multi-thread connections). There’s also a limit of max results, which is 2,000 records per slice/page. All of these rates don’t take AI ingestion into account and assume it’s humans exploring the data.
But simple queries in ScholarXIV Chat require 10’s of papers, if not 100’s, depending on the tier, to give you a reliable and comprehensive output. This number quickly increases if you’re running the research agent for more complex tasks, and arXiv’s API just couldn’t keep up with our rates.
Another setback of the API is that the response is in XML format, so every request we make had to go through a separate pipeline that cleans and normalized the XML data in order to be used in a type-safe and expected format. When we run API intensive queries in ScholarXIV, even internally within our team, we would usually go into rate limit issues, slow load times, and just an unpleasant experience. If just three people faced this issue, you can imagine what will happen after launch when hundreds of people get onboarded.
For months, we’ve been in contact with the arXiv team to negotiate for higher rate limits and support, even if it required payments from us. They were open to helping out and decided to upgrade their systems, but it was going to take longer than we anticipated.
Our Solution
So we had to make one crucial decision before launching ScholarXIV back in May 15. We have to build and host our own database of research papers. So in the days leading up to launch, we built a system and a set of scripts to harvest and sync all of arXiv’s research papers into our own database, all legally. This process deserves its own engineering blog post that includes getting the data, changing it to a format we use, synchronizing, and optimizing the database, all containing documents 3M+ is all very interesting, and we’ll be publishing how we are doing it soon. But simply, we first clone all metadata published up until May 15, 2026, and then every week after that, run a cron job to synchronize any changes to the data.
As soon as we were done building this, we saw an extremely noticeable difference in performance, rate limits, query time, and more. All of a sudden, we could explore thousands of papers almost instantly, we could run our research agents in much higher speeds and rates — which also drastically increased the quality of the response they generated, and we even removed the XML parsing pipeline entirely because our data was in a format we wanted, which also made searching papers much faster.
What then?
If you ever visit arXiv’s support forums, 90% of the conversations there are relating API rates and asking for higher rates; even engineers from Anthropic have been asking for support. So we quickly knew that what we’ve built could help others in their research, AI training, and much more. That’s why we decided to build and release our developers platform to use our Papers API.
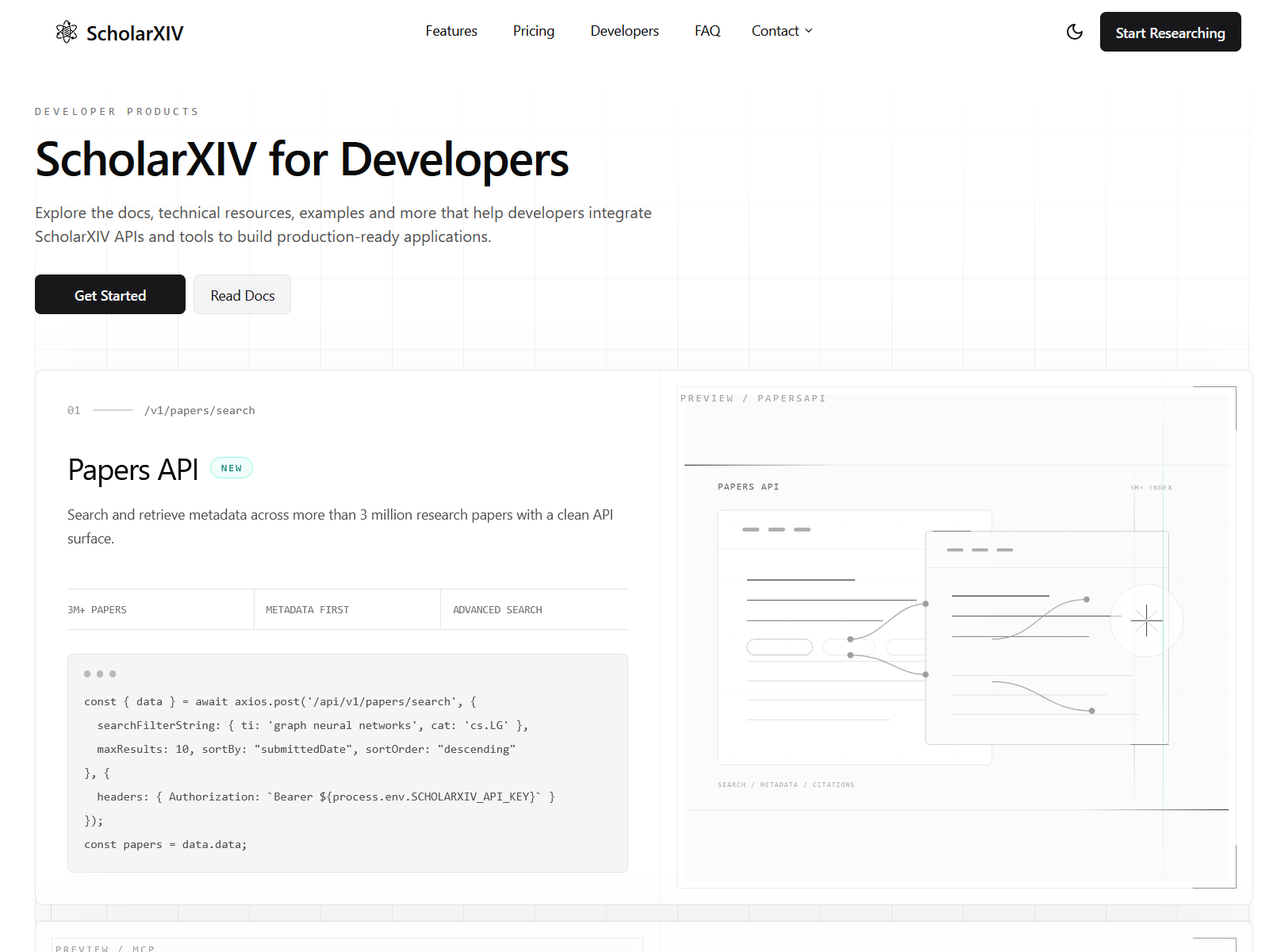
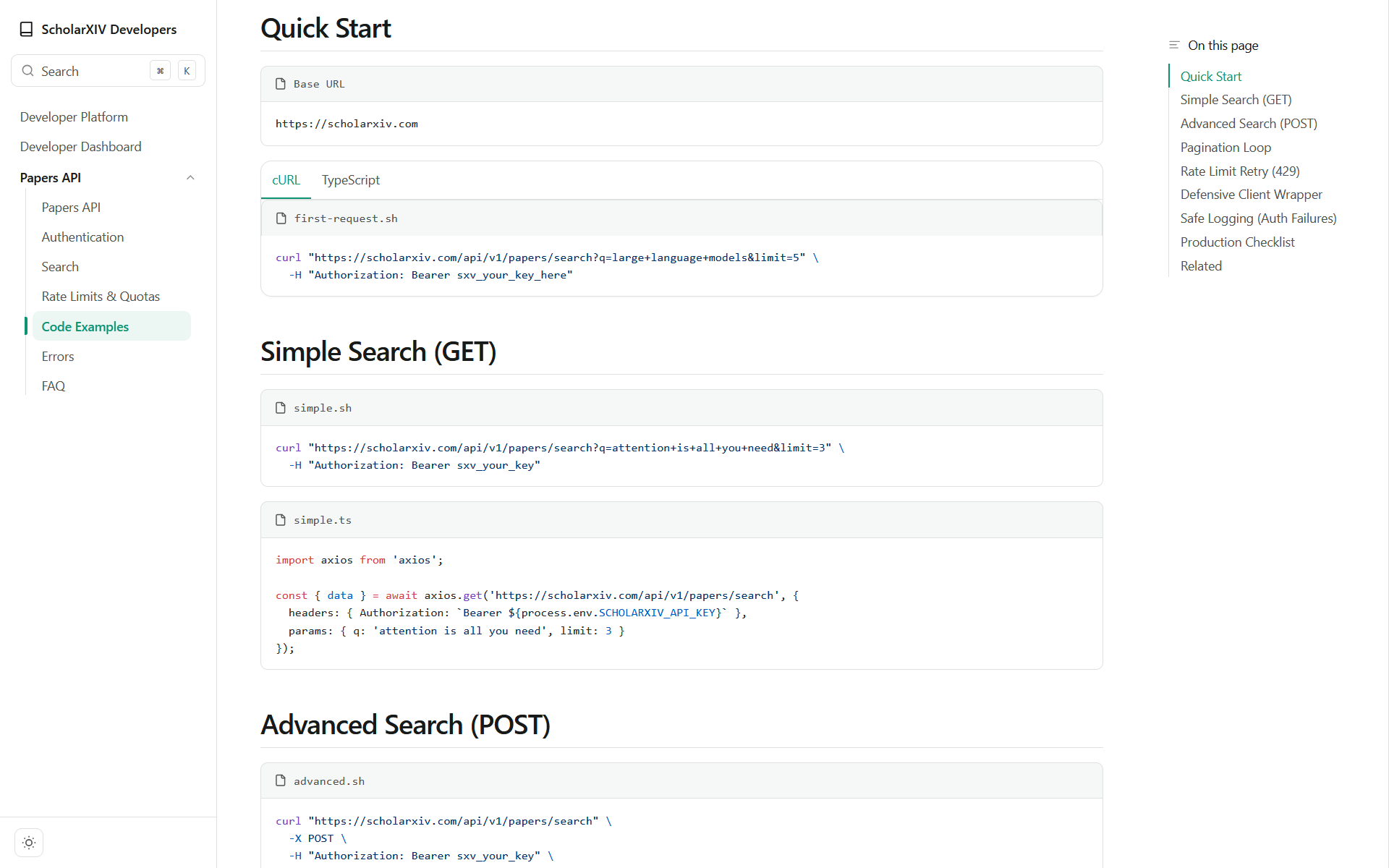
Papers API
This API is built from scratch to make the most of the data we’ve stored. It’s also an extremely easy to use endpoint that you can get started using or just point your AI agents to use. Papers API comes in three-tier subscriptions: Free, Plus, and Pro. The Free tier is a very generous subscription that gives you 1,200 req/hr to get you trying and experimenting with the API before you publish to production — this tier alone outperforms arXiv’s rate limits in speed and efficiency.
The Plus tier gives you 2,400 req/hr, which is 2x the rates of arXiv’s API at much higher speeds and results. The Pro tier is incomparable, giving you 3,600 req/hr, which is 3x compared to arXiv’s API — basically allowing you to make a request every single second of the hour. These are extremely high rates, and nothing comes close; you can imagine what you can do with speeds and limits like these.
The Papers API has two configurations, one is for simple title queries — this is what most people would utilize since titles are more popular than any other content of the papers. But we also offer our advanced query options. These options let you find a needle in a haystack of papers. You can fine-tune by journal, DOI, authors, ID, keyword in the abstract, and just so much more to give you an extremely precise result.
That’s why we’re launching Papers API today in our ScholarXIV Developers Platform.
ScholarXIV Developers Platform
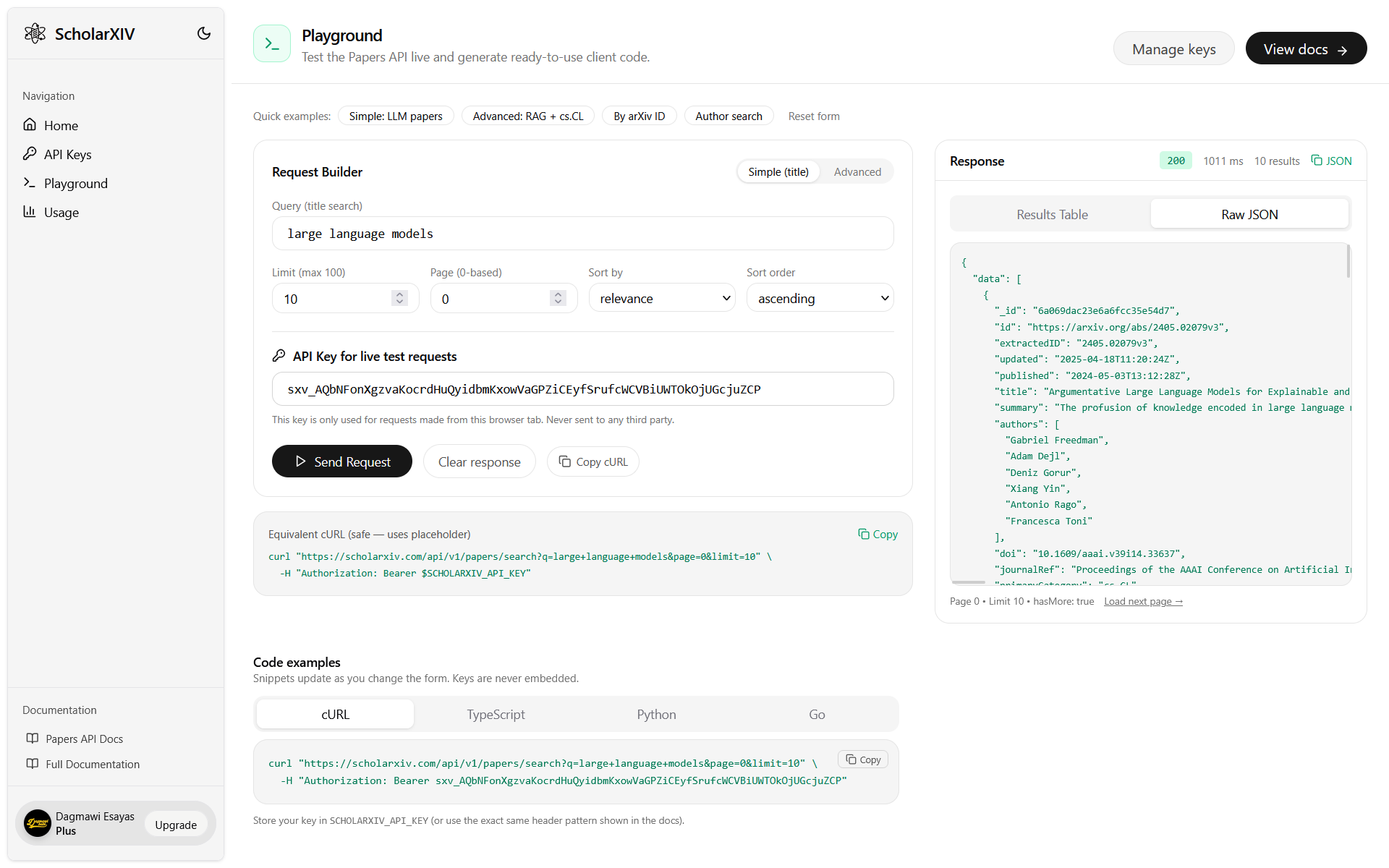
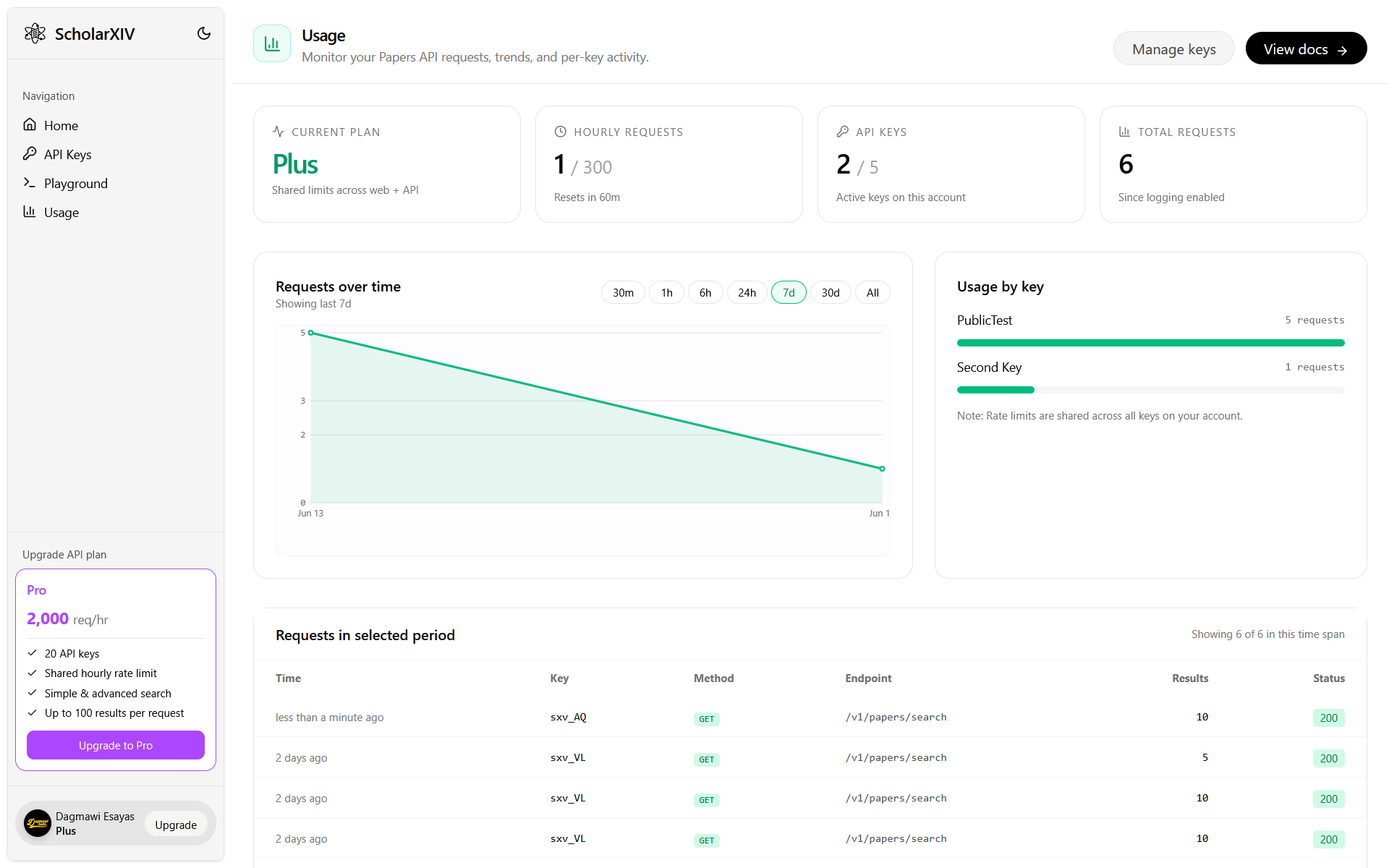
ScholarXIV wants to be as developer-friendly as possible; that’s why we’re also launching ScholarXIV Developers Platform with the initial product being the Papers API. The platform comes with a very comprehensive dashboard, an extensive API Key management feature, an advanced playground to test out queries and analyze responses, and a usage dashboard to monitor use across all your keys.
Playground
Usage
We’ve also made a comprehensive documentation addressing every aspect of the API we’re releasing with simple and easy-to-understand formats, examples, and resources. Our docs are AI-friendly, so you can just grab the llms.txt file or just point your agent to the docs, and it will be AI friendly.
What’s Next?
We’re very busy building some upcoming products, one of which is ScholarXIV MCP, which lets you use ScholarXIV from terminals and from your agents, but that’s not all. We want to own the research stack from data to publishing, to finally achieve the goal of autonomous research. That’s no simple task, so we’ll be locked in and focused on building these and many more!
Can’t wait to see all the amazing things you’re building!